
Веб-серверы
Как объяснялось в первой статье, основная функция веб-сервера - хранить ресурсы и обслуживать их при получении запросов. Вы получаете доступ к веб-серверу с помощью веб-клиента (он же веб-браузер) и взамен получаете запрошенный ресурс или меняете состояние существующих. Доступ к веб-серверам также можно получить автоматически с помощью поисковых роботов, о которых мы поговорим позже в этой статье.

Некоторые из самых популярных веб-серверов и, вероятно, те, о которых вы слышали - это HTTP-сервер Apache, Nginx, IIS, Glassfish и др.
Веб-серверы могут быть самыми разными: от очень простых в использовании до сложных программных продуктов. Современные веб-серверы способны выполнять множество различных задач. Основные задачи, которые должен выполнять веб-сервер:
- Настроить соединение - принять или закрыть клиентское соединение
- Получить запрос - прочитать сообщение HTTP-запроса
- Обработка запроса - интерпретация сообщения запроса и выполнение действия
- Доступ к ресурсу - доступ к ресурсу, указанному в сообщении
- Сформировать ответ - создать сообщение HTTP-ответа
- Отправить ответ - отправить ответ обратно клиенту
- Регистрировать транзакцию - записывать завершенную транзакцию в файл журнала
Я разделю основной поток веб-сервера на несколько этапов. Эти этапы представляют собой очень упрощенную версию потока веб-сервера.
Этап 1. Установка подключения
Когда веб-клиент хочет получить доступ к веб-серверу, он должен попытаться открыть новое TCP-соединение. С другой стороны, сервер пытается извлечь IP-адрес клиента. После этого сервер должен решить, открыть или закрыть TCP-соединение с этим клиентом.
Если сервер принимает соединение, он добавляет его в список существующих соединений и отслеживает данные по этому соединению.
Он также может закрыть соединение, если клиент не авторизован или внесен в черный список (вредоносный).
Сервер также может попытаться определить имя хоста клиента с помощью «обратного DNS». Эта информация может помочь при регистрации сообщений, но поиск имени хоста может занять некоторое время, замедляя транзакции.
Этап 2. Получение/обработка запросов
При синтаксическом анализе входящих запросов веб-серверы анализируют информацию из строки запроса, заголовков и тела (если оно предоставлено). Следует отметить, что соединение может быть приостановлено в любой момент, и в этом случае сервер должен временно хранить информацию, пока он не получит остальные данные.
Высококачественные веб-серверы должны иметь возможность открывать множество одновременных подключений. Это включает несколько одновременных подключений от одного и того же клиента. Типичная веб-страница может запрашивать у сервера множество различных ресурсов.
Этап 3. Доступ к ресурсу
Поскольку веб-серверы в первую очередь являются поставщиками ресурсов, у них есть несколько способов сопоставления ресурсов и доступа к ним.
Самый простой способ сопоставить ресурс - использовать URI запроса для поиска файла в файловой системе веб-сервера. Обычно веб-сервер помещает их в специальную папку, называемую docroot. Например, корневой каталог на сервере Windows может располагаться на F:\WebResources\.
Если запрос GET хочет получить доступ к файлу в /images/codemazeblog.txt, сервер переводит это в F:\WebResources\images\codemazeblog.txt и возвращает этот файл в ответном сообщении. Если на веб-сервере размещено несколько веб-сайтов, для каждого из них может быть свой отдельный корневой каталог.
Если веб-сервер получает запрос каталога вместо файла, он может решить его несколькими способами. Он может вернуть сообщение об ошибке, вернуть индексный файл по умолчанию вместо каталога или просканировать каталог и вернуть HTML-файл с содержимым.
Сервер может также сопоставить URI запроса с динамическим ресурсом - программным приложением, которое генерирует некоторые результаты. Существует целый класс серверов, называемых серверами приложений, предназначенных для подключения веб-серверов к сложным программным решениям и обслуживания динамического контента.
Этап 3. Формирование и отправка ответа
После того, как сервер определил ресурс, который ему необходимо обслуживать, он формирует ответное сообщение. Ответное сообщение содержит код состояния, заголовки ответов и текст ответа, если он был необходим.
Если текст присутствует в ответе, сообщение обычно содержит заголовок Content-Length, описывающий размер тела и заголовок Content-Type, описывающий MIME-тип возвращаемого ресурса.
После генерации ответа сервер выбирает клиента, которому он должен отправить ответ. Для нестабильных подключений серверу необходимо закрыть подключение после отправки всего ответного сообщения.
Этап 4. Ведение журнала
По завершении транзакции сервер регистрирует всю информацию о транзакции в файле. Многие серверы предоставляют настройки ведения журнала.
Прокси-серверы
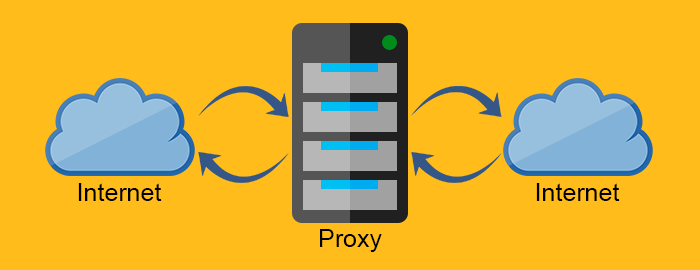
Прокси-серверы являются промежуточными серверами. Они часто находятся между веб-сервером и веб-клиентом. По своей природе прокси-серверы должны вести себя как веб-клиент и веб-сервер.
Но зачем нам прокси-серверы? Почему бы нам просто не общаться напрямую между веб-клиентами и веб-серверами? Разве это не намного проще и быстрее?
Ну, это может быть просто, но быстрее - не совсем. Но к этому мы еще вернемся.
Прежде чем объяснять, что такое прокси-серверы, мы должны уяснить одну вещь. В этом суть обратного прокси или разница между прямым прокси и обратным прокси
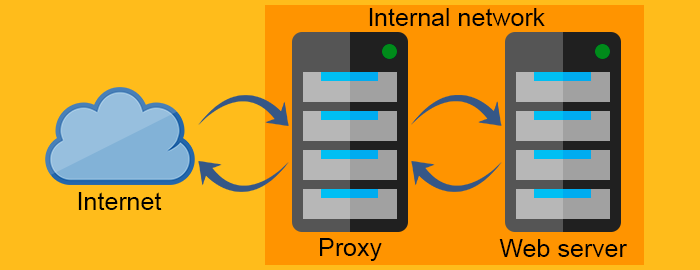
Прямой прокси действует как прокси для клиента, запрашивающего ресурс у веб-сервера. Он защищает клиента, фильтруя запросы через брандмауэр или скрывая информацию о клиенте. С другой стороны, обратный прокси работает с точностью до наоборот. Обычно он размещается за брандмауэром и защищает веб-серверы. Насколько известно клиентам, они общаются с реальным веб-сервером и не знают о сети за обратным прокси.
Прокси-сервер
Обратный прокси-сервер
Прокси-серверы очень полезны, и их применение довольно широко. Давайте рассмотрим несколько способов использования прокси-серверов.
- Сжатие - прямое сжатие контента увеличивает скорость передачи данных. Вот так просто.
- Мониторинг и фильтрация - Хотите запретить доступ к веб-сайтам для взрослых детям начальной школы? Использование прокси-сервера будет правильным решением
- Безопасность. Прокси-серверы могут служить единой точкой входа для всей сети. Они могут обнаруживать вредоносные приложения и ограничивать протоколы на уровне приложений.
- Анонимность - запросы могут быть изменены прокси-сервером для достижения большей анонимности. Он может удалить конфиденциальную информацию из запроса и оставить только важные. Хотя отправка меньшего количества информации на сервер может ухудшить взаимодействие с пользователем, анонимность иногда является более важным фактором.
- Контроль доступа. Довольно просто, вы можете централизовать контроль доступа множества серверов на одном прокси-сервере.
- Кеширование. Вы можете использовать прокси-сервер для кэширования популярного контента, что значительно снизит скорость загрузки.
- Балансировка нагрузки. Если у вас есть служба, которая получает много «пикового трафика», вы можете использовать прокси-сервер для распределения нагрузки на большее количество вычислительных ресурсов или веб-серверов. Балансировщики нагрузки направляют трафик, чтобы избежать перегрузки отдельного сервера в период пика.
- Транскодирование - за изменение содержимого тела сообщения также может отвечать прокси-сервер.
Как видите, прокси-серверы могут быть очень универсальными и гибкими.
Кеширование
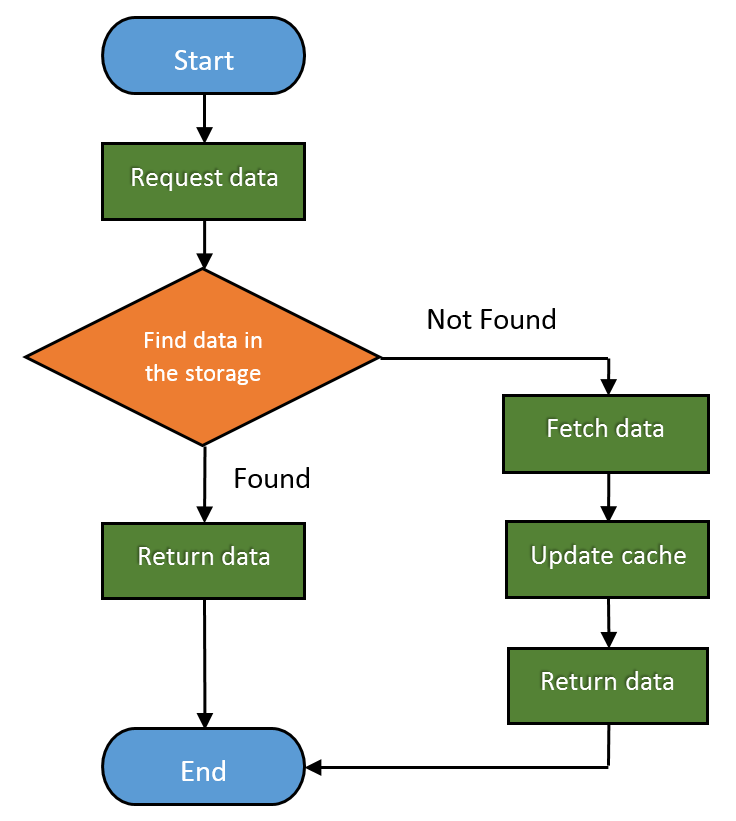
Веб-кеши - это устройства, которые автоматически делают копии запрошенных данных и сохраняют их в локальном хранилище.
Таким образом они могут:
- Уменьшите поток трафика
- Устранение узких мест в сети
- Предотвратить перегрузку сервера
- Уменьшите задержку ответа на больших расстояниях
Таким образом, вы можете четко сказать, что веб-кеш улучшает работу пользователей и производительность веб-сервера. И, конечно же, можно сэкономить много денег.
Доля запросов, обслуживаемых из кеша, называется частотой попаданий. Она может варьироваться от 0 до 1, где 0 - это 0%, а 1 - 100% запросов. Идеальной целью, конечно, является достижение 100%, но реальное число обычно ближе к 40%.
Вот как выглядит основной рабочий процесс веб-кеширования:
Шлюзы, туннели и ретрансляторы
Со временем, когда HTTP стал более зрелым, люди нашли множество различных способов его использования. HTTP стал полезным в качестве основы для подключения различных приложений и протоколов.
Посмотрим, как.
Шлюзы
Шлюзы относятся к частям оборудования, которые позволяют HTTP взаимодействовать с различными протоколами и приложениями, абстрагируя способ получения ресурса. Их также называют преобразователями протоколов, и они намного сложнее маршрутизаторов или коммутаторов из-за использования нескольких протоколов.
Вы можете, например, использовать шлюз для получения файла по FTP, отправив HTTP-запрос. Или вы можете получить зашифрованное сообщение через SSL и преобразовать его в HTTP (шлюзы-ускорители безопасности на стороне клиента) или преобразовать HTTP в более безопасное сообщение HTTPS (шлюзы безопасности на стороне сервера).
Туннели
В туннелях используется метод запроса CONNECT. Он позволяет отправлять данные, отличные от HTTP, через HTTP. Метод CONNECT просит туннель открыть соединение с целевым сервером и передать данные между клиентом и сервером.
Запрос CONNECT:
CONNECT api.github.com:443 HTTP/1.0
User-Agent: Chrome/58.0.3029.110
Accept: text/html,application/xhtml+xml,application/xml
CONNECT ответ:
HTTP/1.0 200 Connection Established
Proxy-agent: Netscape-Proxy/1.1
В ответе CONNECT не требуется указывать Content-Type, в отличие от обычного ответа HTTP.
После установления соединения мы можем напрямую отправлять данные между клиентом и сервером.
Ретрансляторы
Ретрансляторы - это упрощенные версии прокси-серверов, которые передают любую информацию, которую они получают, при условии, что они могут установить соединение, используя минимальную информацию из сообщений запроса.
Единственное существование связано с необходимостью реализовать прокси с минимальными трудностями. Это также может потенциально привести к проблемам, но его использование очень ситуативно и, безусловно, существует соотношение риска и пользы, которое следует учитывать при внедрении ретранслятора.
Веб-сканеры

Также, обычно называемые пауками, это боты, которые ползают по всемирной паутине и индексируют ее содержимое. Таким образом, поисковый робот является важным инструментом для поисковых систем и многих других веб-сайтов.
Сканер - это полностью автоматизированная программа, для работы которой не требуется вмешательство человека. Сложность поисковых роботов может сильно различаться, и некоторые из них представляют собой довольно сложное программное обеспечение (например, то, что используют поисковые системы).
Сканеры используют ресурсы посещаемого веб-сайта. По этой причине на общедоступных веб-сайтах есть механизм, который сообщает сканерам, какие части веб-сайта следует сканировать, или сообщает им, чтобы они вообще ничего не сканировали. Вы можете сделать это с помощью robots.txt (стандарта исключения роботов).
Конечно, поскольку это всего лишь стандартный файл, robots.txt не может помешать незваным поисковым роботам сканировать веб-сайт. Некоторые из злонамеренных роботов включают в себя сборщики электронной почты, спам-боты и вредоносное ПО.
Вот несколько примеров файлов robots.txt:
User-agent: *
Disallow: /
Этот говорит всем краулерам держаться подальше.
User-agent: *
Disallow: /somefolder/
Disallow: /notinterestingstuff/
Disallow: /directory/file.html
И этот относится только к этим двум конкретным каталогам и одному файлу.
User-agent: Googlebot
Disallow: /private/
Вы можете запретить конкретному роботу, как в этом случае.
Но учитывая обширный характер всемирной паутины, даже самые мощные из когда-либо созданных поисковых роботов не могут сканировать и индексировать ее целиком. Вот почему они используют политику выбора, чтобы сканировать самые важные ее части. Кроме того, WWW изменяется часто и динамически, поэтому поисковые роботы должны использовать политику актуальности, чтобы рассчитать, следует ли повторно посещать веб-сайты или нет. А поскольку сканеры могут легко перегружать серверы, запрашивая слишком много информации и слишком быстро, существует политика вежливости. Большинство известных поисковых роботов используют интервалы от 20 секунд до 3-4 минут для опроса серверов, чтобы избежать нагрузки на сервер.
Возможно, вы слышали новости о таинственных и злобных глубинных или темных вебах. Но это не более чем часть Интернета, которая намеренно не индексируется. поисковыми системами, чтобы скрыть информацию.
Заключение
Теперь у вас должно быть еще более четкое представление о том, как работает HTTP, и о том, что это гораздо больше, чем запросы, ответы и коды состояния. Существует целая инфраструктура из различных аппаратных и программных компонентов, которые HTTP использует для реализации своего потенциала как прикладного протокола.
Каждая концепция, о которой я говорил в этой статье, достаточно велика, чтобы охватить всю статью или даже книгу. Нашей целью было в общих чертах представить вам различные концепции, чтобы вы знали, как все это сочетается друг с другом и на что обращать внимание при необходимости.